# setup R libraries used in this post
library(tidyverse, quietly = TRUE)
library(tidycensus, quietly = TRUE)
library(sf, quietly = TRUE)
library(tigris, quietly = TRUE)
library(viridisLite, quietly = TRUE)
library(knitr, quietly = TRUE)
library(scales, quietly = TRUE)
library(kableExtra, quietly = TRUE)
options(tigris_use_cache = TRUE)
options(tigris_class = "sf")Working with New Haven Area Census Data Using R
census
maps
R
Using the tidycensus package to explore census data. This post shows R code to fetch and map census data, but also gives some tips on how to explore the almost overwhelmind variety of variables available via the Census Bureau.
This post will work through a basic setup to look at census data for the New Haven area. It will rely on the tidycensus and tigris packages by Kyle Walker. The emphasis will be on the R code for getting and using Census data rather than on the data itself.
I should emphasize that I am in no way an expert on the Census. On the contrary I would rate myself as a novice. The point of this post is to record my exploration of how to apply the Census to my area of the state. I hope to provide some of the information I wish I had when I first started working with Census data.
American Community Survey
The tidycensus package is designed to retrieve data via the Census Bureau API’s either from the decennial census or from the American Community Survey (ACS). For this exercise I will focus on the ACS.
The ACS started in 2005 and has replaced the “long form” of the census survey. Between 1970 and 2000, the U.S. Census Bureau used two questionnaires. Most households received a short-form questionnaire asking a minimum number of questions. A sample of households received a long-form questionnaire that included additional questions about the household. In 2005 the American Community Survey was created to replace the long form census. The 2010 Census had just one questionnaire consisting of ten questions. (Census Bureau)
By law one is required to respond to Census Bureau surveys, but in practice the Bureau does not levy fines for non-response to the ACS.
Each year about 3% of households are included in the sample for the American Community Survey. It covers a wide range of topics. There’s a page that describes the many topics on the survey and why they are included. It also leads to links where you can see the actual questions as they appear on the ACS. There’s lots of data about race and citizenship and household demographics and money. But there are also quite a few items on other aspects of life. It seems like it has everything, including the kitchen sink (covered by table B25051 Kitchen Facilities for All Housing Units).
As a side note, learning about the American Community Survey has given me a much stronger understanding of the recent controversy (and legal wrangling) about adding a citizenship question to the decennial census. I now appreciate that the Census Bureau has worked to made the decennial census bare bones and simple to respond to. There are a lot of things one might want to know about the US population, and the American Community Survey is their vehicle for getting that depth of information. It is already has questions about citizenship and also lots of detail about national origin. The ACS is designed so that the decennial census does not need to ask about citizenship. The ACS is sufficient and a better vehicle for getting a full picture of citizenship and immigration.
What Variables are in the ACS?
For someone like myself who is unfamiliar with the ACS it can be downright bewildering to sift through what’s available. Using the load_variables function in tidycensus (or by going to the Census Bureau web site) one can download the variable numbers that describe each count that is available from the ACS results. There are over 25,000 rows in the table that lists all these variable numbers. It took me a while to get used to what a “variable” is in this sense. Remember, via the API you are not seeing raw results (i.e., one row per person’s response). The ACS API gives you various tabulations and cross-tabulations. Each variable is one of those tabulations, that is, one number in a table. In fact, variables are organized in terms of topics and tables. There is an ID for each table, (such as B17010) and then separate variables for each cell in that table (and for many of the cross-tabulations as well). A tool that helped me to get used to the meaning of variables is the American Factfinder, an online tool at the Census Bureau web site. The Factfinder has been superseded by a new data exploration platform at census.data.com. Unfortunately, as far as I can tell, the American Factfinder doesn’t display the table numbers used by the API. (It feels like I should be able to get that; perhaps I just don’t know how.) The new data.census.gov does show the overall table number, but not the variable names for individual cells.
When I click on Table Notes on a Factfinder table, I get a popup window with a link to technical documentation. (The same link is also available at data.census.gov.) On the left side of that page there is a guide to other items related to technical documentation. Of particular value is the link to Table Shells. On that page one can find Table Shells for All Detailed Tables as a single 1.3MB excel spreadsheet
As an example, here is the table shell for Table C17010 (which is a collapsed version of the even more detailed Table B17010)1:
POVERTY STATUS IN THE PAST 12 MONTHS OF FAMILIES BY FAMILY TYPE BY PRESENCE OF RELATED CHILDREN UNDER 18 YEARS
| Line# | Variable | Description |
|---|---|---|
| 1 | C17010_001 | Total: |
| 2 | C17010_002 | Income in the past 12 months below poverty level: |
| 3 | C17010_003 | Married-couple family: |
| 4 | C17010_004 | With related children of the householder under 18 years |
| 5 | C17010_005 | Other family: |
| 6 | C17010_006 | Male householder, no wife present |
| 7 | C17010_007 | With related children of the householder under 18 years |
| 8 | C17010_008 | Female householder, no husband present |
| 9 | C17010_009 | With related children of the householder under 18 years |
| 10 | C17010_010 | Income in the past 12 months at or above poverty level: |
| 11 | C17010_011 | Married-couple family: |
| 12 | C17010_012 | With related children of the householder under 18 years |
| 13 | C17010_013 | Other family: |
| 14 | C17010_014 | Male householder, no wife present |
| 15 | C17010_015 | With related children of the householder under 18 years |
| 16 | C17010_016 | Female householder, no husband present |
| 17 | C17010_017 | With related children of the householder under 18 years |
As you work with tidycensus using these variable names will be confusing. Many ACS table are much more elaborate than this one and the array of variable names can be overwhelming. C17010 has 17 lines in the table, but B17010 (the more expanded version) has 41 lines. And there are nine variations of this table by race, indicated by a letter appended to the table name:
- C17010A White alone
- C17010B Black or African American alone
- C17010C American Indian or Alaskan Native alone
- C17010D Asian alone
- C17010E Native Hawaiian or Other Pacific Islander alone
- C17010F Some other race alone
- C17010G Two or more races
- C17010H White alone and not Hispanic or Latino
- C17010I Hispanic or Latino
That adds up to 17 x 10 = 170 variables for all of the variations of C17010. And for B17010 and its variations there are a total of 410 variables. You can see how you can get lost amidst all of these variables.
After writing this section, I realized that C17010 is only available in the one-year version of ACS, and is not available in the five-year version which combines data for 2013 through 2017. I’m leaving the description of C17010 because it is more compact, but in the code below I want to work with the 5-year data (to get better estimates for small geographic units) so I’ll have to stick with B17010. Of course one can always get the same numbers in C17010 by adding the right variables from B17010. I should have paid attention to the “notes” column which has 1 and a 5 when the table is available for both ACS versions and a 1 when it is available only for the single year version.
Note that when you are working with the ACS table shells, you should pay attention to what universe is specified for each table. Some example: families, households, total population, housing units. There are many more specific universes: population 15 years and over in the United States, civilian non-institutionalized population, and so on. The “universe” is the set of things that are being sampled to produce the results in the table.
Get ACS Data Via tidycensus
Once you have zeroed in on which ACS variables you want to look at, the next step is to use tidycensus to retrieve the data via the Census Bureau API. I am going to retrieve data on families below the poverty line for the towns in the New Haven area, my own part of Connecticut.
We will use get_acs() to retrieve the data.
This post was created with RMarkdown and all of the code to fetch the ACS data and to make the plots is included here and is visible.
A preliminary detail. To access US Census items via the Census Bureau API, you will need an API key. You can obtain a key via this link. After they email you your key, you use the census_api_key function to save it for use by tiycensus and tigris functions. It will look like `census_api_key(“YOUR KEY GOES HERE”). The key is stored in your R environment.
You can manually create a list of variables to pass to get_acs(), but it may be easier to work with the long data frame of variable names that one can fetch via load_variables(). Some additional parsing of the returned data can make working with variables much easier. In the code block here we will pull out the table identifiers and also separate out the table variants for breakdowns by race.
vars <- load_variables(2017, "acs5", cache = TRUE) %>%
mutate(table_id = str_sub(name, 1, 6),
# Race generally is in parentheses after the concept name.
# But for a few cases, something else is in parentheses first. So I
# am going to blank out that stuff and then assume whatever I find inside
# of parentheses is race.
concept = str_replace_all(concept,
c("\\(IN 2017 INFLATION-ADJUSTED DOLLARS\\)" = "",
"\\(EXCLUDING HOUSEHOLDERS, SPOUSES, AND UNMARRIED PARTNERS\\)" = "",
"\\(SSI\\)" = "",
"\\(INCLUDING LIVING ALONE\\)" = "",
"\\(IN MINUTES\\)" = "",
"\\(DOLLARS\\)" = "",
"\\(CT, ME, MA, MI, MN, NH, NJ, NY, PA, RI, VT, WI\\)" = "--CT, ME, MA, MI, MN, NH, NJ, NY, PA, RI, VT, WI--",
"\\(CAR, TRUCK, OR VAN\\)" = "--CAR, TRUCK, OR VAN--",
"\\(\\)" = ""
)),
race = str_extract(concept, "\\(.+\\)"),
race = str_replace(race, "\\(", ""),
race = str_replace(race, "\\)", ""))
# I should have been able to do this in one line, but it doesn't seem to work:
# race = str_extract(concept, "\\((.*?)\\)"))
B17010_variables <- vars %>%
filter(table_id == "B17010", is.na(race)) %>%
pluck("name")
poverty_acs <- get_acs(geography = "county subdivision", # for CT, that means towns
state = "CT",
county = "New Haven",
geometry = "FALSE", # no map at this time
year = 2017,
survey = "acs5",
variables = B17010_variables[2],
summary_var = B17010_variables[1]) %>%
filter(estimate > 0) %>%
mutate(TOWN = str_replace(NAME, " town, New Haven County, Connecticut", ""),
pct_poverty = estimate / summary_est,
pct_moe = moe_prop(estimate, summary_est, moe, summary_moe)) Via the parameters of the function, we told the get_acs function that we want data by town (geography = “county subdivision”), that we wanted the five-year ACS data ending in year 2017 (the latest available as of April, 2019), that we want variable B17010_002 (the estimate of the total number of families below the poverty line). We have also asked that B17010_001 be added as a summary variable, in this case the estimate of the total number of families in the geographic unit. The percentage of the number of families below the poverty line can thus be calculated as estimate divided by summary_est. The tidycensus package also supplies some functions for estimating the margin of error when you combine or summarize estimates. See the tidycensus help for moe_sum and moe_prop for notes on how to estimate margin of error when doing arithmetic operatons on ACS estimates such as addition or using a ratio to calculate a percentage.
pick_towns <- c("Woodbridge", "West Haven", "New Haven", "East Haven",
"Bethany", "Orange", "Milford", "Branford", "Guilford",
"North Haven", "Madison", "Hamden", "North Branford",
"Wallingford")
branford <- poverty_acs %>% filter(TOWN == "Branford") # for example
poverty_acs <- poverty_acs %>%
filter(TOWN %in% pick_towns) %>%
arrange(desc(pct_poverty))
nh_pct_poverty <- percent(poverty_acs$estimate[[1]] / sum(poverty_acs$estimate), accuracy = 1)
nh_pct_families <- percent(poverty_acs$summary_est[[1]] / sum(poverty_acs$summary_est), accuracy = 1)
poverty_formatted <- poverty_acs %>%
arrange(desc(pct_poverty)) %>%
filter(TOWN %in% pick_towns) %>%
mutate(pct_poverty = percent(pct_poverty, accuracy = 1),
pct_moe = paste0("±", percent(pct_moe, accuracy = .1)),
moe = paste0("±", moe),
summary_moe = paste0("±", summary_moe)) %>%
select(GEOID, Town = TOWN, `Below Poverty` = estimate, MOE = moe, `Total # of Families` = summary_est, `MOE of Families` = summary_moe, `% Poverty` = pct_poverty, `MOE of %` = pct_moe)
kable(poverty_formatted, format.args = list(big.mark = ","),
caption = "Families Below Poverty Line (from Table B17010)", label = NA) %>%
kableExtra::kable_styling() %>%
kableExtra::footnote(general = "Source: US Census American Community Survey 2013-2017 (variable B17010_002)\ntidycensus R package")| GEOID | Town | Below Poverty | MOE | Total # of Families | MOE of Families | % Poverty | MOE of % |
|---|---|---|---|---|---|---|---|
| 0900952070 | New Haven | 5,038 | ±468 | 24,699 | ±584 | 20% | ±1.8% |
| 0900982870 | West Haven | 1,055 | ±267 | 11,563 | ±460 | 9% | ±2.3% |
| 0900922910 | East Haven | 438 | ±194 | 6,802 | ±296 | 6% | ±2.8% |
| 0900935650 | Hamden | 534 | ±187 | 13,974 | ±410 | 4% | ±1.3% |
| 0900947535 | Milford | 507 | ±163 | 13,841 | ±340 | 4% | ±1.2% |
| 0900978740 | Wallingford | 421 | ±148 | 11,879 | ±350 | 4% | ±1.2% |
| 0900907310 | Branford | 227 | ±115 | 7,325 | ±307 | 3% | ±1.6% |
| 0900904580 | Bethany | 45 | ±42 | 1,611 | ±107 | 3% | ±2.6% |
| 0900957600 | Orange | 97 | ±65 | 3,836 | ±117 | 3% | ±1.7% |
| 0900954870 | North Haven | 137 | ±61 | 6,261 | ±216 | 2% | ±1.0% |
| 0900934950 | Guilford | 122 | ±62 | 6,343 | ±193 | 2% | ±1.0% |
| 0900987700 | Woodbridge | 38 | ±32 | 2,249 | ±156 | 2% | ±1.4% |
| 0900944560 | Madison | 76 | ±48 | 5,066 | ±158 | 2% | ±0.9% |
| 0900953890 | North Branford | 55 | ±53 | 4,075 | ±208 | 1% | ±1.3% |
| Note: | |||||||
| Source: US Census American Community Survey 2013-2017 (variable B17010_002) tidycensus R package |
The table displays the basic data returned by the call to get_acs. Note that there is a margin of error (MOE) for each count. ACS is based on a sample and is subject to sampling error. Plus or minus the MOE is the 90% confidence interval for the estimate. As one looks at small geographic units, MOE can be a big issue. For example, in this data there are an estimated 7,325 families in Branford, plus or minus 307. That’s a range of about 7%. But for Branford the estimate for the number of families below the poverty line is both small and unreliable: 227 with an MOE of 115. If I had used the one-year ACS rather than the five-year, the MOE would be even worse. In fact, the API will not even return the one-year results for most towns. If I run the get_acs code but with ACS1 rather than ACS5 I only get data returned for New Haven and Waterbury, the two largest towns in the county. The MOE for total number of families in New Haven goes from ±584 for ACS5 to ±1,358 for ACS1. And for the number of families below the poverty line, the MOE goes from ±468 to ±925. The one-year ACS has rules for what data will not be reported because the sample is too small. The ACS5 will give you the results, but that doesn’t mean you should be oblivious to whether a large MOE indicates a comparison you want to make is not valid.
The table confirms that poverty is concentrated in the city. While 21% of families of the 14 towns are in New Haven, 57% of families below the poverty line are in New Haven. And some other tracts with elevated levels of poverty are in East Haven and West Haven adjacent to the city.
Basic Map
At this point we have a simple example of using the Census API to get data from the ACS. Next we are going to do some basic mapping and then show how to use those technique to map data from the ACS.
To begin we will create a basic map for Connecticut towns surrounding the City of New Haven. The Census Bureau provides extensive resources for geographic information and maps via its TIGER (Topologically Integrated Geographic Encoding and Referencing) products. The tigris package provides a simple way to get basic maps (represented as shapefiles) that are most relevant to census tabulations. There are many types of geographic units available. In our case we will focus on county, towns (in the case of New England, county subdivisions in TIGER terminology), and census tracts. Towns are especially relevant in Connecticut (and in New England in general). The rest of the country relies on census tracts within counties.
To create the maps I will use the relatively new sf (simple features) package. The sf package is designed to be tidyverse compatible. One can use the usual dplyr verbs to manipulate sf objects and use the geom_sf function to add maps to ggplot2. Before sf was created, I had to rely on the sp package, which was much less convenient. (There are links to six vignettes describing sf at the CRAN sf package page.)
There are 28 towns, boroughs, or cities in New Haven County. The county goes as far north as Waterbury. I decided to focus on the 14 towns that I think of as being the City of New Haven and its suburbs:
Milford, Orange, Woodbridge, Bethany,
Hamden, West Haven, Wallingford, North Haven,
East Haven, Branford, North Branford, Guilford,
Madison, and New Haven. It turns out this list is very similar to the South Central Regional Council of Governments. The one difference is that SCRCOG also includes Meriden, which I excluded as being too far north and therefore outside of the immediate New Haven orbit.
The code in the next section uses tigris to retrieve shapefiles for the census tracts and towns (county subdivisions) in New Haven County. There may be some direct way via tigris to relate towns to census tracts. I had to do it indirectly. I use the st_centroid function to find the center of each census tract and then use the sf_join function with the st_intersects join to join towns to tracts to show which goes with which. Each geographic object in TIGER has a GEOID identifier. The tract_town object has a column for TOWN.GEOID and another for TRACT.GEOID. I turn that into a regular data frame that I can join to other sf objects so that I can associate towns with tracts via tract GEOID.
pick_towns <- c("Woodbridge", "West Haven", "New Haven", "East Haven",
"Bethany", "Orange", "Milford", "Branford", "Guilford",
"North Haven", "Madison", "Hamden", "North Branford",
"Wallingford")
# I'm saving these to make it easier to re-use same code for a different area.
pick_county = "New Haven"
pick_state = "CT"
# set cb = TRUE to keep boundaries tied to the coastline
town_geometry <- county_subdivisions(state = pick_state, county = pick_county, cb = TRUE)
tract_geometry <- tracts(state = pick_state, county = pick_county, cb = TRUE)
# let's find which tract is in which town
tract_centroid = st_centroid(tract_geometry)
# tract town has the geometry of town, not tract
tract_town <-st_join(town_geometry, tract_centroid,
join = st_intersects,
suffix = c(".TOWN", ".TRACT"))
tract_town_df <- tract_town %>%
as_tibble() %>%
select(TOWN = NAME.TOWN, GEOID = GEOID.TRACT) %>%
mutate(near_nh = (TOWN %in% pick_towns))
area_tracts <- tract_geometry %>%
left_join(tract_town_df, by = "GEOID") %>%
filter(TOWN %in% pick_towns)
area_towns <- town_geometry %>% filter(NAME %in% pick_towns)
area_town_centroid <- st_centroid(area_towns) # use to place town labelsCreate a Map of New Haven Area
Next we will use ggplot2 and the geom_sf geom to create a map from the sf objects that contain the shapefiles for tracts and towns around New Haven.
ggplot() +
geom_sf(data = area_tracts,
fill = "gray", colour = "darkgray", show.legend = FALSE) +
geom_sf(data = area_towns, colour = "yellow", fill = NA) +
geom_sf_text(data = area_town_centroid, aes(label = NAME), color = "yellow") +
coord_sf(datum = NA, label_axes = "----") +
xlab("") + ylab("") + theme_minimal() +
labs(title = "New Haven Area Towns",
subtitle = "with census tract boundaries",
caption = "Source: US Census, tidycensus package") 
We Have a Map; Let’s Display Some Census Data
I am going to retrieve the poverty data at the level of census tract and display the result. Keep in mind that the margin of error for a particular tract will be quite large. Comparing similar census tracts may be misleading, although it still should be clear that the poor areas in the cities are much different than the suburbs. Let’s try it and see what happens and afterward we will explore the issue of margin of error a bit more.
I have redone the get_acs query we did by town, only this time the geography unit will be tracts rather than county subdivisions.
poverty_tracts <- get_acs(geography = "tract",
state = "CT",
county = "New Haven",
geometry = "TRUE", # yes, get tract shapefiles
year = 2017,
survey = "acs5",
variables = B17010_variables[2],
summary_var = B17010_variables[1]) %>%
filter(estimate > 0) %>%
mutate(pct_poverty = estimate / summary_est,
pct_moe = moe_prop(estimate, summary_est, moe, summary_moe)) %>%
left_join(tract_town_df, by = "GEOID") %>%
filter(TOWN %in% pick_towns)# poverty_tracts is similar to poverty_acs, but includes geometry and limits to area towns
ggplot() +
geom_sf(data = poverty_tracts,
aes(fill = pct_poverty), colour = "lightgray") +
scale_fill_viridis_c(option = "plasma", direction = -1, name = "Pct Poverty", begin = 0.1) +
geom_sf(data = area_towns, colour = "darkgray", fill = NA) +
geom_sf_text(data = area_town_centroid, aes(label = NAME), color = "darkgray") +
coord_sf(datum = NA, label_axes = "----") +
xlab("") + ylab("") + theme_minimal() +
labs(title = "Percentage of Families Below the Poverty Line",
subtitle = "by census tract (margin of error by tract may be large)",
caption = "Source: US Census American Community Survey 2013-2017 (variable B17010_002)\ntidycensus R package") 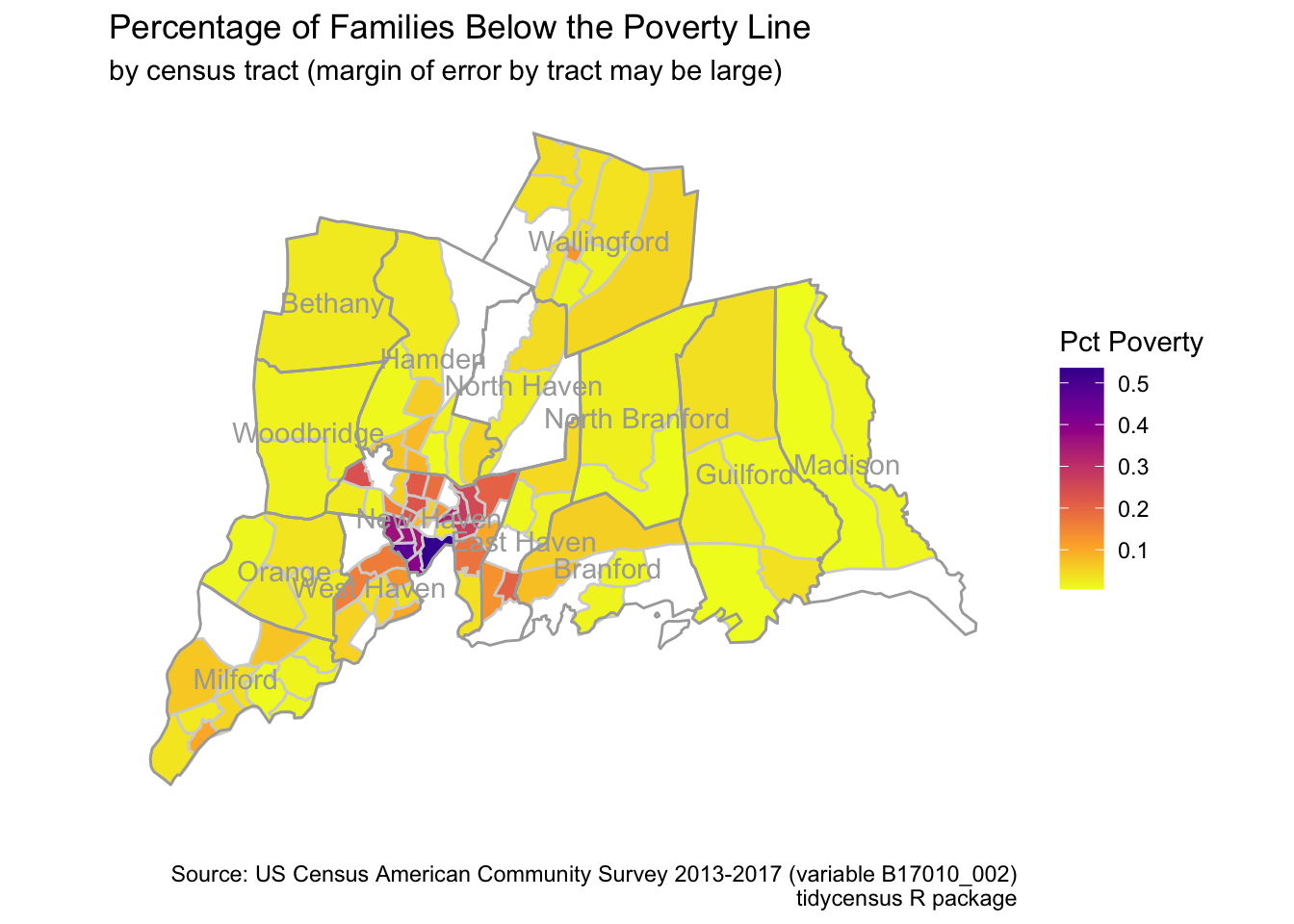
In the map that shows poverty by census tract, there are six tracts that are missing from the data. They show up as white areas on the map. Presumably data has been suppressed. One of the missing tracts is where I used to live in New Haven. Families below the poverty line may have been hard to find there. I don’t know how the suppression policies work for the five-year ACS so I don’t know why these tracts are missing.
# INCOME IN THE PAST 12 MONTHS B07411_0.5
income_tracts <- get_acs(geography = "tract",
state = "CT",
county = "New Haven",
geometry = "TRUE",
year = 2017,
survey = "acs5",
variables = "B19013_001") %>%
filter(estimate > 0) %>%
left_join(tract_town_df, by = "GEOID") %>%
filter(TOWN %in% pick_towns)
ggplot() +
geom_sf(data = income_tracts,
aes(fill = estimate), colour = "gray") +
scale_fill_viridis_c(option = "plasma", direction = -1, name = "Income", begin = 0.1,
trans = "log", breaks = c(20000, 30000, 50000, 100000, 150000)) +
geom_sf(data = area_towns, colour = "white", fill = NA, size = 0.5) +
geom_sf_text(data = area_town_centroid, aes(label = NAME), color = "darkgray") +
coord_sf(datum = NA, label_axes = "----") +
xlab("") + ylab("") + theme_minimal() +
labs(title = "Median Household Income (Log Scale)",
subtitle = "by census tract (margin of error by tract may be large)",
caption = "Source: US Census American Community Survey 2013-2017 (variable B19013_001)\ntidycensus R package") 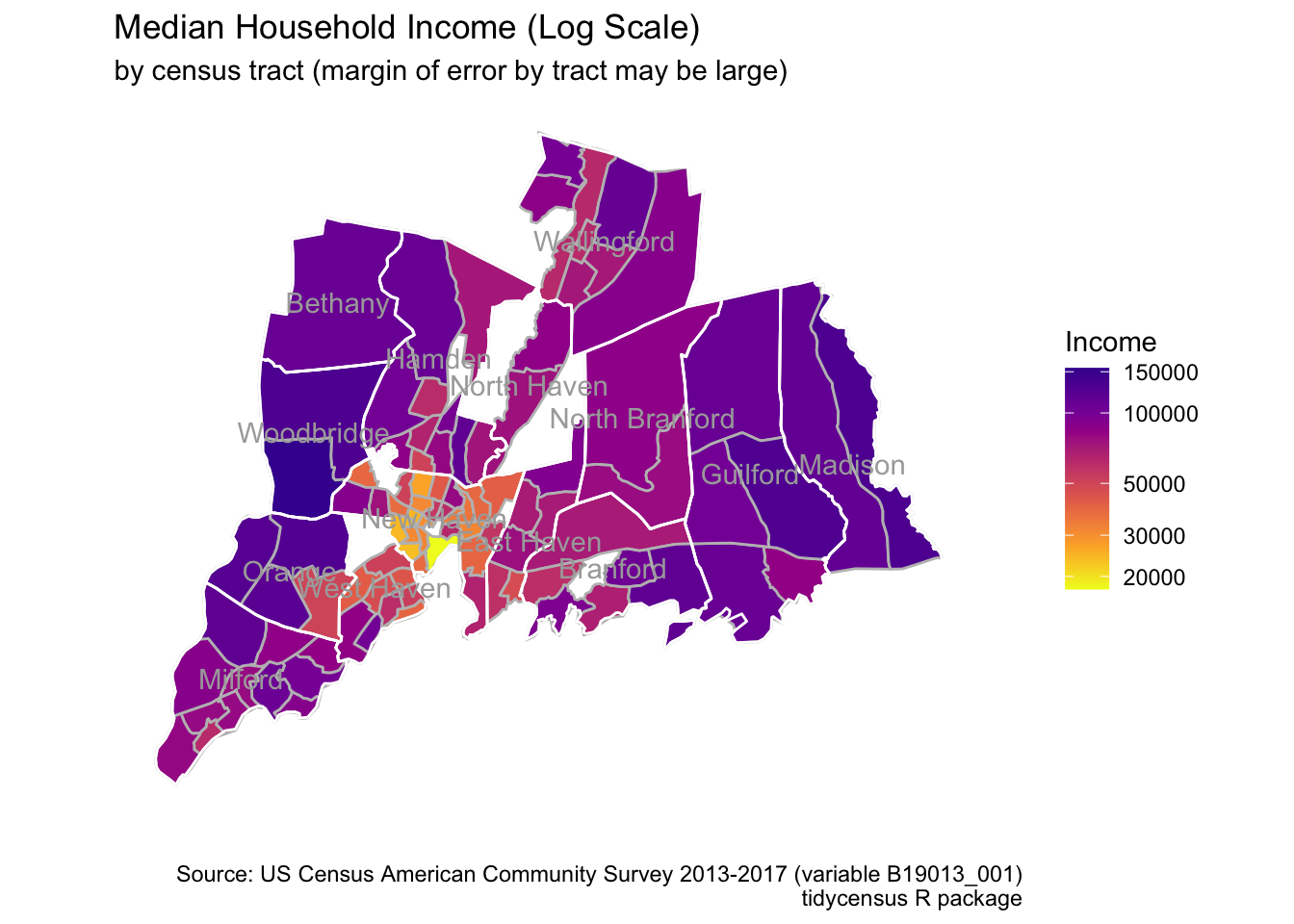
Because the ACS is based on a sample, one cannot ignore the margin of error. The next plot has shows the median income for each census tract within each town drawn with a line that represents minus and plus the margin error. In effect this shows a 90% confidence interval. Where the lines overlap you should not draw the conclusion that one census tract is higher than another. On the other hand, one see cases where it is clear there is a difference. Track 1571 in Orange is unambiguously lower than the other tracts in Orange.
area_towns_order <- c("Bethany", "Woodbridge", "Wallingford", "North Branford",
"Orange", "Hamden", "North Haven", "Guilford",
"West Haven", "New Haven", "Branford", "Madison",
"Milford", "East Haven")
income_tracts <- income_tracts %>%
mutate(tract_name = str_sub(NAME, 8, (str_locate(NAME, ",")[, 1] - 1)),
TOWN = factor(TOWN, levels = area_towns_order))
ggplot(data = income_tracts, aes(x = estimate/1000, y = fct_reorder(tract_name, estimate))) +
geom_point() +
geom_errorbarh(mapping = aes(xmin = (estimate - moe)/1000, xmax = (estimate + moe)/1000), height = 0) +
facet_wrap(~ TOWN, scales = "free_y") +
ylab(NULL) +
labs(title = "90% Confidence Interval for Median Household Income",
subtitle = "(Income is Displayed on a Log Scale)",
caption = "Source: US Census American Community Survey 2013-2017 (variable B19013_001)\ntidycensus R package") +
scale_x_log10(name = "Income (000's)", breaks = c(20, 30, 50, 100, 150)) +
theme(axis.text.x = element_text(size=6), axis.text.y = element_text(size=5))
Now for Something Completely Different
The next ACS query will focus on mode of transportation to work. This is an example of the breadth of the survey. In addition to the material shown here, there’s also a lot on the time it takes to get to work.
vars2 <- vars %>% filter(table_id == "B08006") %>%
separate(label, into = paste0("t", seq(1, 8)), remove = FALSE, sep = "!!") %>%
select(-t1)
# to supplement picking out variables manually, in this step we will parse the
# label and use that info to help select variables.
vars2 <- vars2 %>% filter(is.na(t4)) %>%
mutate(commute_mode = case_when(
is.na(t3) ~ "All workers",
str_detect(t3, "^Car") ~ "Vehicle",
str_detect(t3, "Public") ~ "Public Transport",
str_detect(t3, "Bicycle") ~ "Bicycle",
str_detect(t3, "Walked") ~ "Walked",
str_detect(t3, "Taxi") ~ "Taxi, motorcycle",
str_detect(t3, "^Worked") ~ "At home",
TRUE ~ "Other")
)
for_summary <- vars2 %>% filter(commute_mode == "All workers") %>% pluck("name")
vars2 <- vars2 %>% filter(commute_mode != "Other", commute_mode != "All workers")
# At this point, variables are in vars2$name
# SEX OF WORKERS BY MEANS OF TRANSPORTATION TO WORK B08006
commuters <- get_acs(geography = "county subdivision", # for CT, that means towns
state = "CT",
county = "New Haven",
geometry = "FALSE",
year = 2017,
survey = "acs5",
variables = vars2$name,
summary_var = for_summary) %>%
filter(estimate > 0) %>%
left_join(town_geometry %>% select(-NAME), by = "GEOID") %>%
mutate(TOWN = str_replace(NAME, " town, New Haven County, Connecticut", ""),
pct = estimate / summary_est,
pct_moe = moe_prop(estimate, summary_est, moe, summary_moe)) %>%
filter(TOWN %in% pick_towns) %>%
left_join(vars2 %>% select(variable = name, commute_mode), by = "variable")
commuters_table <- commuters %>%
select(commute_mode, pct, TOWN) %>%
spread(key = commute_mode, value = pct) %>%
arrange(Vehicle) %>%
mutate_if(is.numeric, percent)Transportation to Work
The ACS reports the mode of transportation to work. For workers, the table below shows the percentage who rely primarily on each form of transportation (plus a column for workers who work at home). The table is sorted by the percentage who travel by car.
kable(commuters_table, caption = "Mode of Transportation to Work", lab = NA) %>%
kableExtra::kable_styling() %>%
kableExtra::footnote(general = "Source: US Census American Community Survey 2013-2017 (variable B08006)\ntidycensus R package")| TOWN | At home | Bicycle | Public Transport | Taxi, motorcycle | Vehicle | Walked |
|---|---|---|---|---|---|---|
| New Haven | 4.1825% | 3.056% | 12.359% | 0.9942% | 66.837% | 12.571% |
| Madison | 9.8785% | 0.710% | 3.646% | 0.9626% | 84.274% | 0.529% |
| West Haven | 3.3653% | 0.096% | 6.226% | 0.2248% | 86.318% | 3.771% |
| Guilford | 7.8807% | NA | 2.318% | 0.3674% | 87.746% | 1.688% |
| Hamden | 3.0827% | 0.627% | 4.210% | 0.4294% | 88.160% | 3.490% |
| Milford | 4.7260% | 0.021% | 4.973% | 0.5392% | 88.381% | 1.360% |
| Woodbridge | 7.7015% | 0.454% | 2.774% | 0.2153% | 88.424% | 0.431% |
| Orange | 5.9053% | 0.217% | 3.046% | 0.4909% | 89.691% | 0.650% |
| Bethany | 6.7881% | NA | 1.179% | 0.7145% | 90.640% | 0.679% |
| East Haven | 3.7225% | 0.085% | 2.663% | 0.5368% | 90.669% | 2.324% |
| Branford | 4.1840% | 0.145% | 2.072% | 0.7127% | 90.774% | 2.112% |
| Wallingford | 4.8982% | 0.004% | 0.735% | 0.5204% | 91.856% | 1.987% |
| North Haven | 4.1027% | NA | 2.306% | 1.2165% | 92.089% | 0.286% |
| North Branford | 2.6022% | NA | 0.320% | 0.3205% | 96.193% | 0.564% |
| Note: | ||||||
| Source: US Census American Community Survey 2013-2017 (variable B08006) tidycensus R package |
white_not_hispanic <- "B01001H_001"
white_alone <- "B02008_001"
black <- "B02009_001"
asian <- "B02011_001"
hispanic <- "B01001I_001"
not_us <- "B05001_006"
# let's get the variables into a data frame where they will be easier to work with
rcodes <- tribble(
~code, ~variable,
"white_not_hispanic" , "B01001H_001",
"white_alone" , "B02008_001",
"black" , "B02009_001",
"asian" , "B02011_001",
"hispanic" , "B01001I_001",
"not_us" , "B05001_006")
race_town2 <- get_acs(geography = "county subdivision", # for CT, that means towns
state = "CT",
county = "New Haven",
geometry = "FALSE",
year = 2017,
survey = "acs5",
variables = c(white_not_hispanic, white_alone, black, hispanic, asian, not_us),
summary_var = "B01001_001") %>%
left_join(rcodes, by = "variable") %>%
mutate(race = factor(code,
levels = c("white_alone", "white_not_hispanic", "hispanic", "black", "asian", "not_us"),
labels = c("White alone", "White not Hispanic", "Hispanic", "Black", "Asian", "Not US citizen")),
pct = estimate / summary_est,
pct_moe = moe_prop(estimate, summary_est, moe, summary_moe))
race_town <- town_geometry %>% left_join(race_town2 %>% select(-NAME), by = "GEOID") %>%
filter(NAME %in% pick_towns)
race_table <- as_tibble(race_town %>%
select(Town = NAME, code, summary_est, pct, pct_moe, race))
race_table <- race_table %>%
mutate(pct = percent(pct, accuracy = 1.0)) %>%
select(Town, race, Percent = pct) %>%
spread(key = race, value = Percent) %>%
arrange(`White not Hispanic`) Race by Town
The following table shows race by town. The ACS has a lot of detail on race, more than is presented in this table. The Census Bureau (and other agencies) now use what is referred to as the “two question” format for asking about race. The first question is whether or not the individual is Hispanic and then a second question asks about race/ethnicity. On the second question, the individual can select multiple categories. In many tables the non-Hispanic categories are presented as “alone”, meaning the individual chose only that category. But because Hispanic is a second question, “White alone” (or other alone categories) can also self-identify as Hispanic. In the table below, “White not Hispanic” means the person selected “White” (or some other race category) and did not select Hispanic. “White alone” means the person selected only “White” among the race categories regardless of the response to the Hispanic question. Notice that for New Haven, “White not Hispanic” is 30% of the population while “White alone” is 46%. A substantial number of Hispanics also said White.
The citizenship category is completely separate from race and simply indicates whether a respondent was not a US citizen.
Note that the categories as I have defined them here can add up to more than the total population. This is a tricky area of the ACS. There are some other tables that get into the issue of how the multiple categories are used.
race_table %>% kable(caption = "Percent Race by Town (Categories are not mutually exclusive)",
lab = NA) %>%
kableExtra::kable_styling() %>%
kableExtra::footnote(general = "Source: US Census American Community Survey 2013-2017\nvariables B01001H_001, B02008_001, B02009_001, B02011_001, B01001I_001, B05001_006\ntidycensus R package")| Town | White alone | White not Hispanic | Hispanic | Black | Asian | Not US citizen |
|---|---|---|---|---|---|---|
| New Haven | 46% | 30% | 30% | 35% | 5% | 12% |
| West Haven | 67% | 51% | 21% | 24% | 4% | 9% |
| Hamden | 65% | 58% | 11% | 25% | 6% | 7% |
| East Haven | 86% | 77% | 15% | 4% | 5% | 3% |
| Woodbridge | 82% | 77% | 5% | 2% | 16% | 6% |
| North Haven | 88% | 83% | 5% | 4% | 8% | 3% |
| Milford | 90% | 84% | 7% | 4% | 6% | 5% |
| Wallingford | 92% | 85% | 8% | 2% | 5% | 2% |
| Bethany | 94% | 86% | 6% | 1% | 6% | 3% |
| Orange | 91% | 87% | 2% | 2% | 8% | 4% |
| Branford | 93% | 88% | 5% | 2% | 5% | 3% |
| North Branford | 94% | 89% | 5% | 4% | 2% | 1% |
| Guilford | 96% | 91% | 4% | 1% | 4% | 2% |
| Madison | 96% | 93% | 1% | 1% | 4% | 3% |
| Note: | ||||||
| Source: US Census American Community Survey 2013-2017 variables B01001H_001, B02008_001, B02009_001, B02011_001, B01001I_001, B05001_006 tidycensus R package |
Next we will see multiple plots that plot each of these categories on the map of towns around New Haven. We can see that the Black population is primarily in New Haven, West Haven, and Hamden. I was surprised to see that there is a notable Asian population in Woodbridge. As we saw in the table, most of the outer suburban towns are very, very white.
ggplot() +
geom_sf(data = race_town,
aes(fill = pct), colour = "lightgray") +
# using the begin parameter of viridis prevents the extremem values from looking almost black
scale_fill_viridis_c(option = "plasma", direction = -1, name = "Pct", begin = 0.2) +
geom_sf(data = area_towns, colour = "darkgray", fill = NA, size = 0.05) +
geom_sf_text(data = area_town_centroid, aes(label = NAME), color = "darkgray", size = 2) +
coord_sf(datum = NA, label_axes = "----") +
xlab("") + ylab("") + theme_minimal() +
facet_wrap(~ race) +
labs(title = "Percentage of Population for a Set of Sub-Groups",
# subtitle = "by census tract (margin of error by tract may be large)",
caption = "Source: US Census American Community Survey 2013-2017 (variables B01001H_001, B02008_001, B02009_001, B02011_001, B01001I_001, B05001_006)\ntidycensus R package") 
As an experiment, I redid the race plot to show detail by census tract not just by town. Of course the overall impression is similar to the town level plots. As I have said before, as one gets down to the level of individual tracts the fact that we are dealing with a sample with a margin of error is an important reason not to over-interpret small vaiations.
race_tracts <- get_acs(geography = "tract",
state = "CT",
county = "New Haven",
geometry = "TRUE",
year = 2017,
survey = "acs5",
variables = c(white_not_hispanic, white_alone, black, hispanic, asian, not_us),
summary_var = "B01001_001") %>%
filter(estimate > 0) %>%
left_join(tract_town_df, by = "GEOID") %>%
filter(TOWN %in% pick_towns) %>%
mutate(pct = estimate / summary_est,
pct_moe = moe_prop(estimate, summary_est, moe, summary_moe)) %>%
left_join(rcodes, by = "variable") %>%
mutate(race = factor(code,
levels = c("white_alone", "white_not_hispanic", "hispanic", "black", "asian", "not_us"),
labels = c("White alone", "White not Hispanic", "Hispanic", "Black", "Asian", "Not US citizen")))
ggplot() +
geom_sf(data = race_tracts,
aes(fill = pct), colour = NA) +
# using the begin parameter of viridis prevents the extremem values from looking almost black
scale_fill_viridis_c(option = "plasma", direction = -1, name = "Pct", begin = 0.2) +
geom_sf(data = area_towns, colour = "darkgray", fill = NA, size = 0.05) +
geom_sf_text(data = area_town_centroid, aes(label = NAME), color = "darkgray", size = 2) +
coord_sf(datum = NA, label_axes = "----") +
xlab("") + ylab("") + theme_minimal() +
facet_wrap(~ race) +
labs(title = "Percentage of Population for a Set of Sub-Groups",
subtitle = "by census tract (margin of error by tract may be large)",
caption = "Source: US Census American Community Survey 2013-2017\n(variables B01001H_001, B02008_001, B02009_001, B02011_001, B01001I_001, B05001_006)\ntidycensus R package") 
As a final step I focused only on the City of New Haven. By focusing on one town only, we can see more detail by census tract. Within the city, some tracts are very white and others are very non-white. The east side of the city tends to be more Hispanic (including the Fair Haven area) and the west side tends to be more Black (the Hill). The census tract where I lived for over 25 years near East Rock is almost as white as the outer suburbs. Two tracts to the west is the blackest tract in New Haven (which I assume is Newhallville).
As before, it is important to remember that at the level of individual census tracts the ACS sample results may not be exactly precise. Small differences between tracts may be within the margin of error.
# I explored possibilit of adding roads, but didn't like it.
# nh_roads <- roads("CT", "New Haven") %>%
# filter(RTTYP %in% c("I", "S", "U"))
# nh_roads <- st_intersection(nh_roads, area_towns %>% filter(NAME == "New Haven"))
nh_focus <- race_tracts %>% filter(TOWN == "New Haven")
ggplot() +
geom_sf(data = nh_focus,
aes(fill = pct), colour = NA) +
# using the begin parameter of viridis prevents the extremem values from looking almost black
scale_fill_viridis_c(option = "plasma", direction = -1, name = "Pct", begin = 0.2) +
geom_sf(data = area_towns %>% filter(NAME == "New Haven"),
colour = "darkgray", fill = NA, size = 0.05) +
geom_sf_text(data = area_town_centroid %>% filter(NAME == "New Haven"),
aes(label = NAME), color = "darkgray", size = 4) +
coord_sf(datum = NA, label_axes = "----") +
xlab("") + ylab("") + theme_minimal() +
facet_wrap(~ race) +
labs(title = "Focus on New Haven: Percentage of Population for a Set of Sub-Groups",
subtitle = "by census tract (margin of error by tract may be large)",
caption = "Source: US Census American Community Survey 2013-2017\n(variables B01001H_001, B02008_001, B02009_001, B02011_001, B01001I_001, B05001_006)\ntidycensus R package") 
Conclusion
The point of all this was to try out the R-based techniques for both extracting and displaying ACS data. My primary aim wasn’t to tell a story about life around New Haven. But the plots do emphasize that where people live is highly correlated with important variables such as income and race.
That comes as no surprise, but perhaps it was even more true than I assumed. I live with these patterns everyday and take them for granted. The plots make the existence of these patterns more salient.
Sources
In the text I have tried to give some tips on how to find one’s way among the abundance of topics and variables in the ACS. Of course there is much, much more info at census.gov.
All of this relies on the tidycensus and tigris packages by Kyle Walker. Several years ago I did a wee bit of work on making maps with census data without tidycensus or the sf package. It was much more difficult! The tools that Kyle has provided make it all much easier. I took his census course at DataCamp and found it to be very helpful.
In addition to tidycensus there is also a censusapi package that provides access to Census Bureau API’s other than the ACS or the decennial census.